Today, the various sites I host on my home server fell off the face of the Earth after some routine backups completed last night. This post just goes through what happened, how it happened, and what I’m doing to ensure that we can respond faster.
As alluded to in previous posts, the web server where this blog runs on is on a virtual machine, which is hosted on an old desktop PC running Windows Server 2012 R2 under HyperV. This makes backing it up pretty straightforward: turn off the virtual machine, make a copy of the virtual hard drive, and turn it back on. This has been happening for a while without issues. As I’m running my web server out of my home, it required me to forward ports 80 and 443 to the correct server, since we’re using network address translation (NAT), which is, of course, typical in a home network.
In addition to this, I run a web server for the SFU Anime Club, which we use primarily for YOURLS. In order for this work, I had to set up a reverse proxy on Apache. This allows my primary server to receive all requests, and for those that have host *.sfuani.me, they get proxied through and sent to the SFU Anime Club’s web server. It looks something like this:
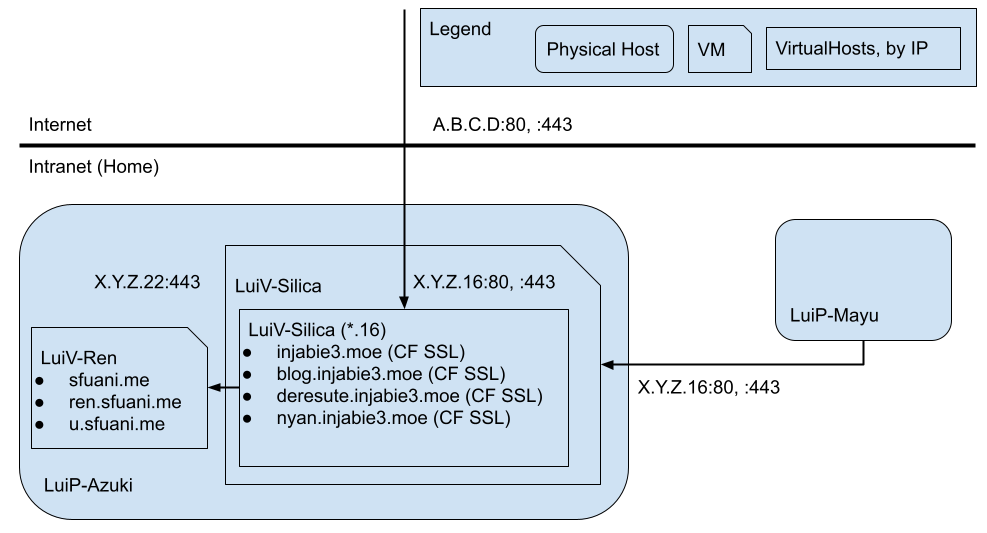
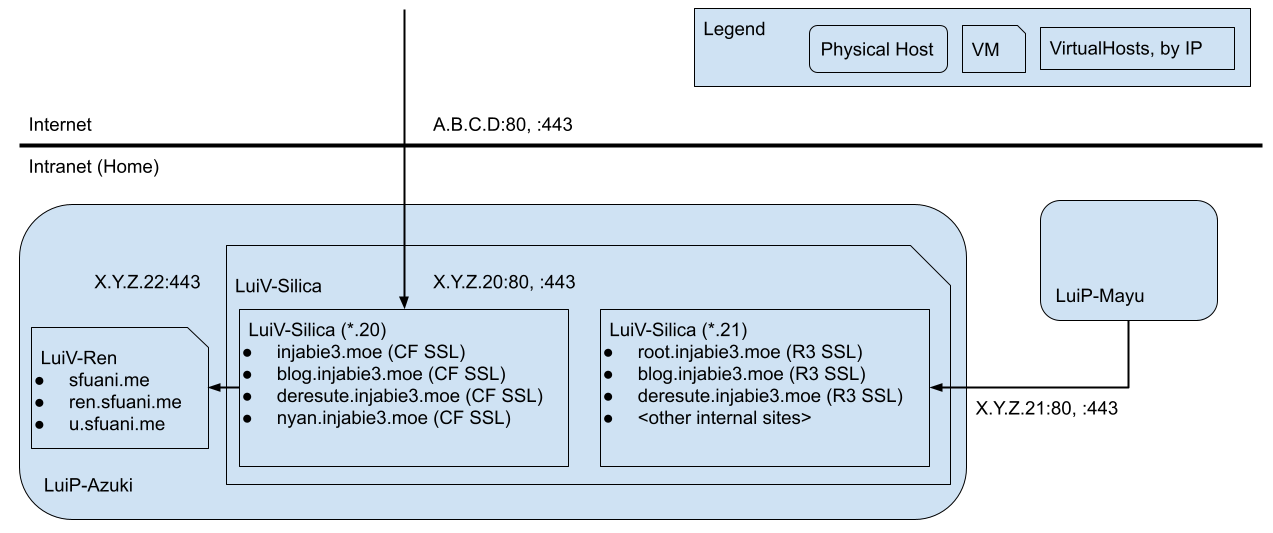
Last month, my domain disappeared off the face of the Earth. As part of that fallout, I had to create an additional network interface to have HTTPS work on my internal network due to Active Directory’s DNS taking precedence on my internal network. As part of that change, I updated the local IP addresses on those interfaces so that they were contiguous, with one IP configured to serve external network requests and the other for internal requests, respectively (i.e. .20 and .21). Luckily (or unfortunately, as I would later find out), Google Wi-Fi automatically detected that the IP changed, and changed the mapping to the new one. I presume that this was detected because the MAC address was the same but the IP address changed. With that, the diagram looks something like below. All is well.
Last night, my server started its monthly backup, which went through as expected: the virtual machines shut down safely, Windows made a copy on an external drive, and started it up back up. As part of this process, StatusCake reported that it was down.

When I woke up in the morning, I noticed that it was still offline. I did a quick reboot, and saw that the URL shortener warning disappeared, and I went to work. I got pinged at around 10:30 about a report that it was down, and spent 15 to 20 minutes trying to root cause the issue at 11:00 to no avail. I rebooted the server, but couldn’t figure it out. At one point, I saw internal sites starting to show up externally, so I pulled the plug and disabled Apache until I had a chance to look at it after work.
Off work, I took a look, and wiped out all of my active VirtualHost configurations. I enabled an external VirtualHost and a default parked site, but I was only met with the parked site. After checking the server logs and checking port forwarding, I pinpointed it to port forwarding. What ended up happening after the server rebooted was that for some reason, the port forwarding swapped to the internal facing IP address itself, similar to this diagram:
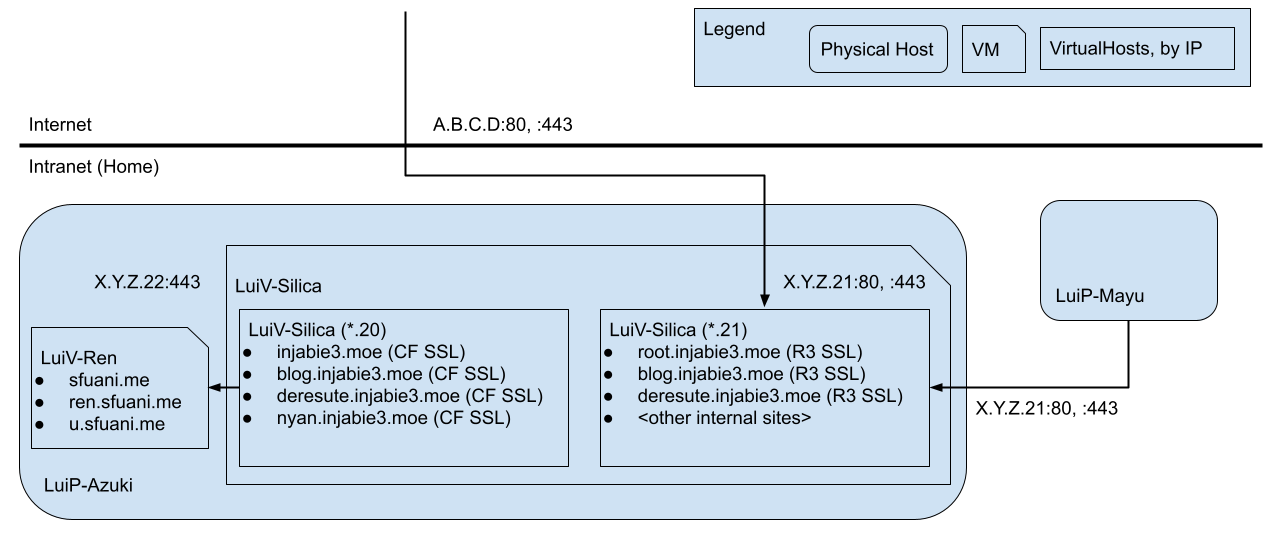
Because Google Wi-Fi pointed to the .21 instance, the server had no idea how to serve pages for u.sfuani.me. It ended up serving the internal pages and my blog, which was indeed what I observed at one point. The server probably also served the other R3 (Let’s Encrypt) certificate when I saw the blog, but because I was using CloudFlare, I would’ve had no chance of seeing it unless I turned off proxying everything through it. I still have no idea how this happened, but removing the port forwarding configuration and then re-adding it solved the problem:
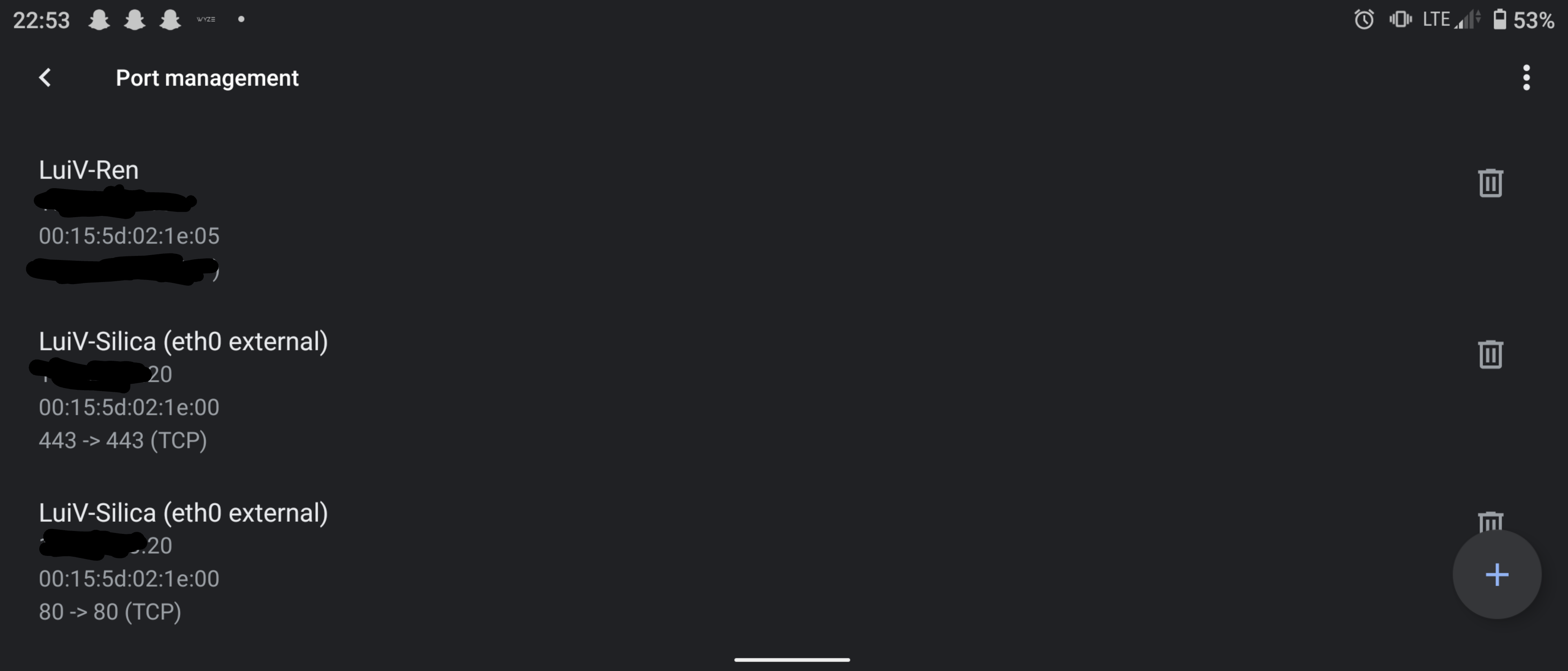
I don’t expect to be changing IPs anytime soon again, so this issue should not recur again, but that was one strange issue that had me very frustrated and annoyed for a good chunk of the day. I’m glad I figured it out at the end. Perhaps this is a lesson on starting fresh (with respect to port forwarding rules) when using Google Wi-Fi for this type of thing.
In order to better detect a similar issue, I have added additional StatusCake checks to better target certain endpoints that can only exist on a specific VirtualHost. This way, it’s evident that something is clearly wrong should it arise again. This has been updated on my public server status page.
Anyways, that’s all I have this time, gonna get some rest for work tomorrow.
Until next time!
~Lui

[…] opted for two separate Apache2 containers because I ran into an issue last year with internal sites being accidentally exposed to the Internet. Having internal and external sites […]